

힙 자료구조에 대해서 알아보자.
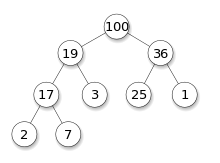
힙 자료구조는 우선순위 큐 (Priority Queue)를 구현하기 위하여 사용하는 자료구조 중 하나다. 'DFS/BFS'를 공부할 때 스택과 큐의 원리에 대해서 알아봤는데 스택은 가장 나중에 삽입된 데이터를 가장 먼저 삭제하고, 큐는 가장 먼저 삽입된 데이터를 가장 먼저 삭제한다.
우선순위 큐는 우선순위가 가장 높은 데이터를 가장 먼저 삭제한다는 점이 특징이다.
| 자료구조 | 추출되는 데이터 |
| 스택(Stack) | 가장 나중에 삽입된 데이터 |
| 큐(Queue) | 가장 먼저 삽입된 데이터 |
| 우선순위 큐(Priority Queue) | 가장 우선순위가 높은 데이터 |
우선순위 큐는 데이터를 우선순위에 따라 처리하고 싶을 때 사용한다. 예를 들어 여러 개의 물건 데이터를 자료구조에 넣었다가 가치가 높은 물건 데이터부터 꺼내서 확인해야 하는 경우를 가정해보자. 이런 경우에 우선순위 큐 자료구조를 이용하면 편리하다.
우선순위 큐가 필요할 때 PriorityQueue , heapq를 사용할 수 있는데, 이 두 라이브러리는 모두 우선순위 큐 기능을 지원한다. 다만 Priority Queue보다는 일반적으로 heapq가 더 빠르게 동작하기 때문에 수행 시간이 제한된 상황에서는 heapq를 사용하자.
대부분의 프로그래밍 언어에서는 우선순위 큐 라이브러리에 데이터의 묶음을 넣으면, 첫 번째 원소를 기준으로 우선순위를 설정한다. 따라서 데이터가 (가치,물건)으로 구성된다면 '가치' 값이 우선순위 값이 되는 것이다.
우선순위 큐를 구현할 때는 내부적으로 최소 힙 혹은 최대 힙을 이용한다. 최소 힙을 이용하는 경우 '값이 낮은 데이터가 먼저 삭제' 되며
최대 힙을 이용하는 경우 '값이 가장 큰 데이터가 먼저 삭제' 된다. 다익스트라 최단 경로 알고리즘에서는 비용이 적은 노드를 우선하여 방문하므로 최소 힙 구조를 기반으로 하는 우선순위 큐 라이브러리를 그대로 사용하면 적합하다.
| 우선순위 큐 구현 방식 | 삽입 시간 | 삭제시간 |
| 리스트 | O(1) | O(N) |
| 힙(Heap) | O(logN) | O(logN) |
데이터의 개수가 N일 때, 힙 자료구조에 N개의 데이터를 모두 넣은 뒤에 다시 모든 데이터를 꺼낸다면 시간 복잡도는 삽입할 때 O(logN)의 연산을 N번 반복하므로 O(logN)이고 삭제할 때도 O(logN)의 연산을 N번 반복하므로 O(NlogN)이다. 따라서 전체 시간 복잡도는 O(NlogN)이 될 것이다.
최소 힙을 이용하는 경우 힙에서 원소를 꺼내면 '가장 값이 작은 원소'가 추출되는 특징이 있으며, 파이썬의 우선순위 큐 라이브러리는 최소 힙에 기반한다는 점을 알고 있자.
'Algorithm' 카테고리의 다른 글
| [BOJ/백준] 2941번 크로아티아 알파벳 (0) | 2020.12.08 |
|---|---|
| [이코테] 최단 경로 알고리즘 (0) | 2020.12.03 |
| [프로그래머스] 더 맵게 (0) | 2020.12.03 |
| [BOJ/백준] 1157번 단어 공부 (0) | 2020.11.30 |
| [BOJ/백준] 10809번 알파벳 찾기 (0) | 2020.11.30 |